AI Cloud Hosting Meets Local Infrastructure: Why You Need Both
Cloud AI hosting is powerful, but the strongest AI teams are learning where local infrastructure changes the cost, privacy, and latency equation.
How OneInfer Edge Knows If Your Machine Can Run Any Hugging Face Model Before You Deploy It
Paste a model ID. OneInfer Edge scans your GPU, VRAM, OS, and installed serving libraries, then gives you a Hardware Ready verdict before deployment.
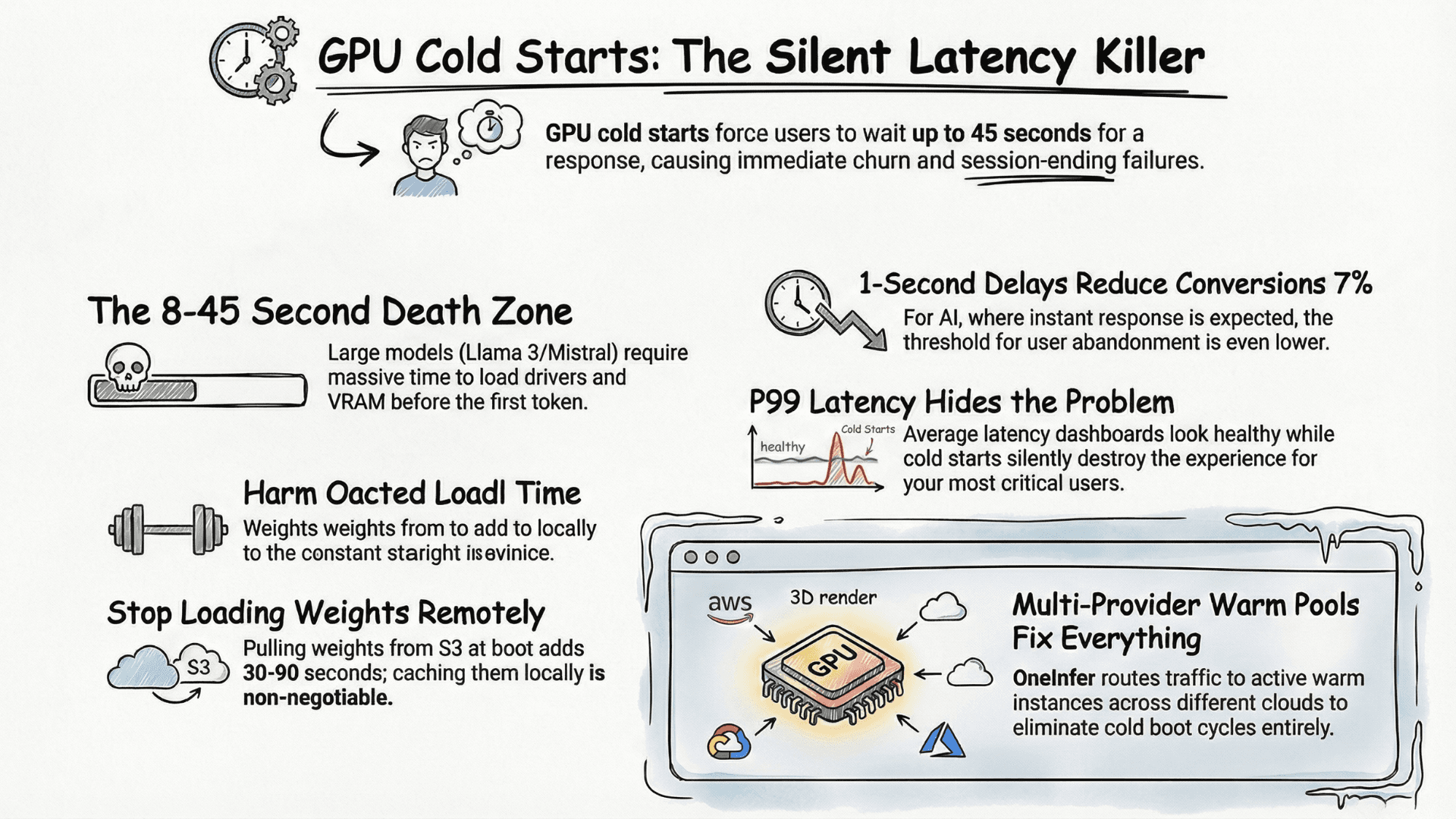
GPU Cold Starts Are Killing Your Inference Latency — Here's the Fix
The first request hits your model. You wait. Two seconds. Four. Eight. Your user has already gone.
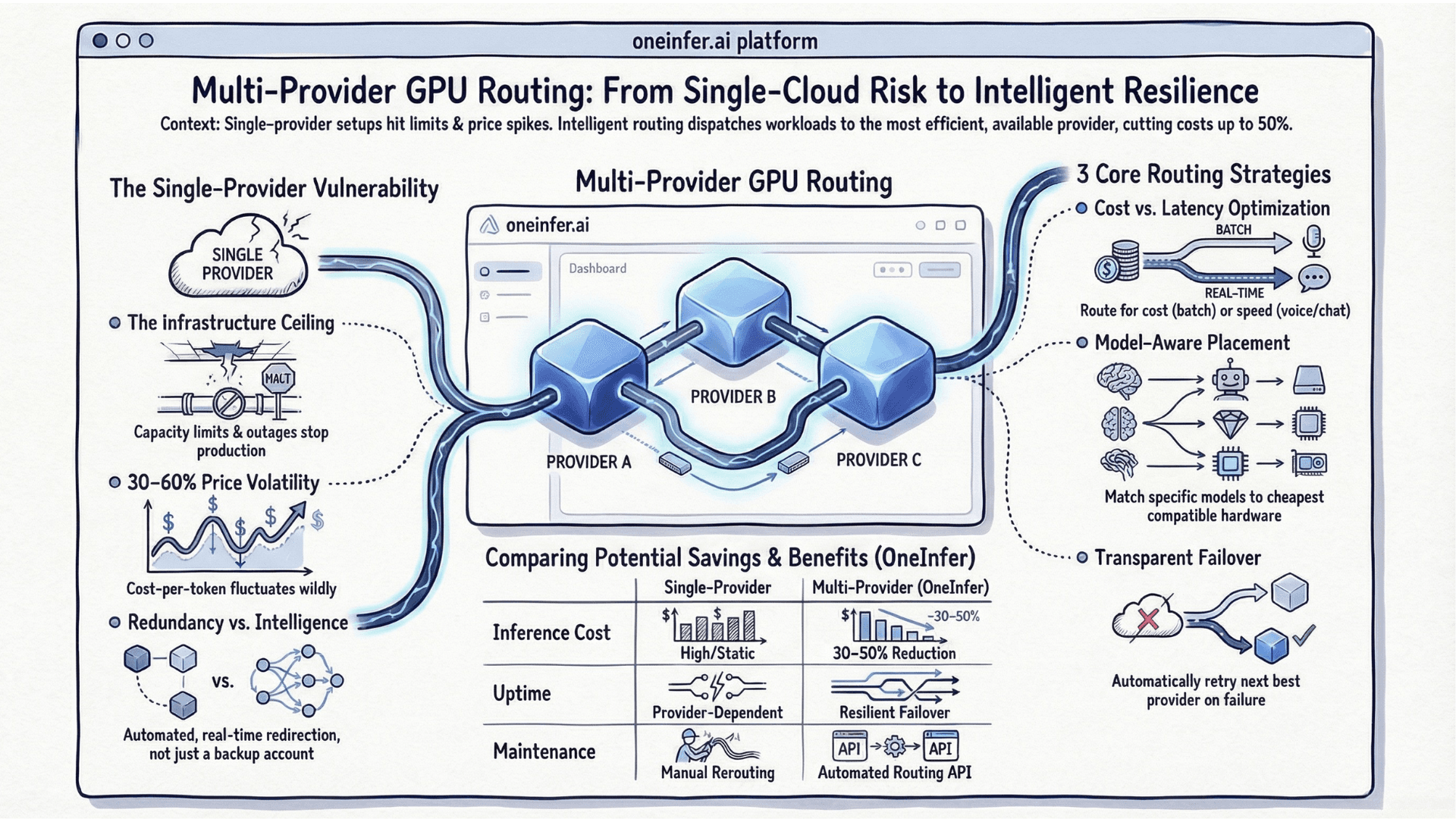
Multi-Provider GPU Routing: A Practical Guide for AI Teams
You've built your model. It's in production. Traffic is growing. And your single GPU cloud provider is starting to show its edges - capacity limits at peak hours, pricing that shifts without warning, a regional outage that costs you an entire Saturday afternoon.
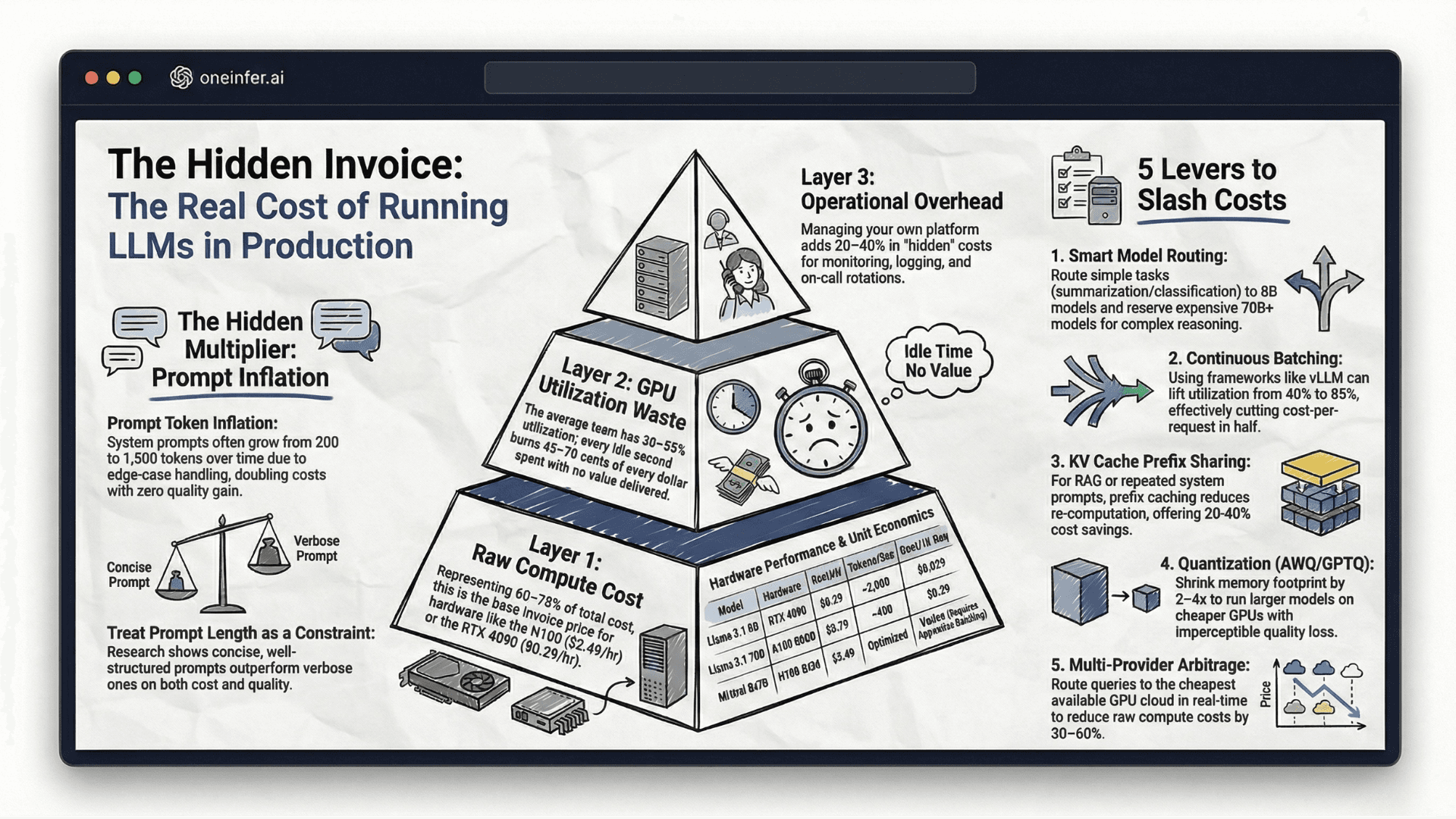
The Real Cost of Running LLMs in Production (With Numbers)
Everyone talks about the cost of training AI models. Nobody talks honestly about what it actually costs to run them at scale.

Why Your AI Infrastructure Breaks at 3AM (And How to Fix It)
It's always 3AM.

From Zero to Production: Deploying LLMs on Multi-GPU Clouds
You've picked your model. You've tested it locally. It runs beautifully on your machine with Ollama. Now you need to get it to production - serving real users, at real scale, with real reliability.

We Saved 60% on GPU Costs — Here's Exactly How
Six months ago, our GPU bill was the largest single line item in our infrastructure spend. It was growing 40% month-over-month and we couldn't precisely trace why.

Triton vs CUDA Kernels: Which Should You Optimize For?
If you're optimizing AI inference at the kernel level, you've arrived at the point where the framework no longer helps you. You're staring at GPU utilization numbers that should be higher, latency that should be lower, and a decision: drop into CUDA C++, or write Triton kernels in Python.

Building AI Infra for Startups: Mistakes We Made (So You Don't)
We started OneInfer because we made nearly every infrastructure mistake in the book building previous AI products. This is the honest version of that story - not a polished retrospective, but the actual mistakes, the actual costs, and what we would do differently if we were starting today.

Avoid These 7 Cost Surprises When You Scale AI Inference
You ran a successful AI pilot. The model hit your accuracy targets. Stakeholders signed off on the roadmap. You got the green light to scale.

How to Run Production-Grade Model Inference with Sub-Millisecond Latency
Latency is not a performance metric. It is a product metric.

Add an AI Feature to Your Product in 30 Days — A PM's Technical Roadmap
Most product teams treat adding an AI feature as an infrastructure project. It isn't. It is a product decision that requires infrastructure support — and getting that distinction right is what separates teams that ship AI features in 30 days from teams that are still in sprint planning six months later.

White-Label AI Features — How Agencies Build New Revenue With Inference APIs
Your clients are asking for AI. Not in a vague, exploratory way — in a specific, budgeted, deadline-attached way. They want intelligent search in their e-commerce platform. They want automated content generation in their CMS. They want predictive analytics in their reporting dashboard. They want it in the next quarter, and they want to see your proposal by end of month.

Unified AI Inference — Run Any Model With One API
Your ML team uses PyTorch. Your computer vision pipeline runs TensorFlow SavedModels. Your NLP team deploys Hugging Face transformers. Your recommendation engine runs ONNX. Each of these has its own serving stack, its own monitoring configuration, its own scaling policies, and its own on-call runbook.

Reducing AI Inference Costs by 80% — Strategies That Actually Work
Most AI teams are overspending on inference by a larger margin than they realize. The inefficiency is not concentrated in one place — it is distributed across every layer of the stack, accumulating quietly until the monthly GPU bill arrives and the numbers do not match the budget projections.

Enterprise-Grade AI Inference — Security, Scale, and Reliability
Enterprise AI deployment is categorically different from startup AI deployment — not because the models are different, but because the operational requirements surrounding them are.