TL;DR
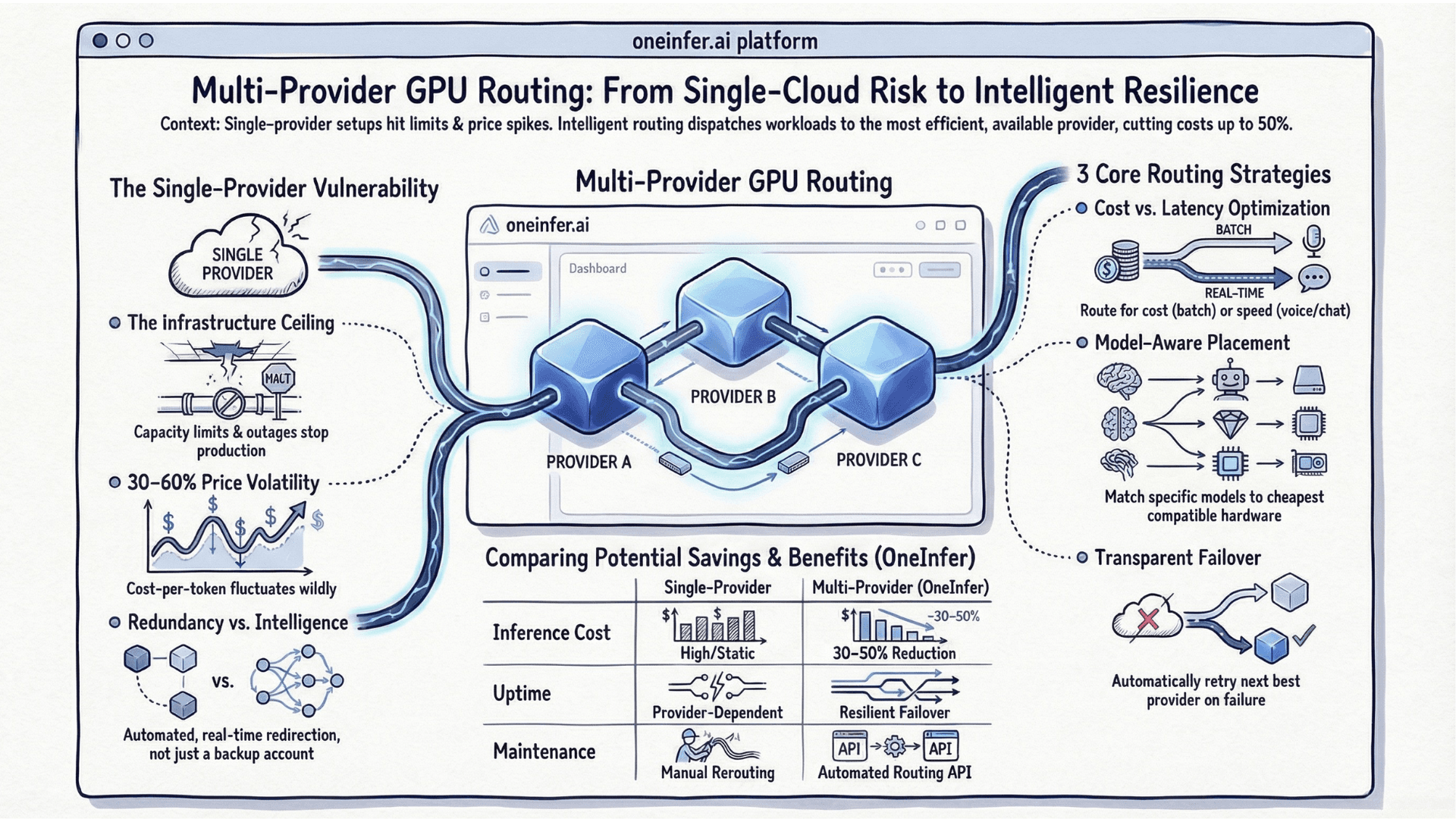
Multi-provider GPU routing reduces inference cost 30–50% and improves uptime by automatically directing each request to the optimal provider based on real-time price, latency, and availability. The four core strategies are cost-first, latency-first, model-aware, and failover routing. The hardest implementation problems are state synchronization, token-level billing reconciliation, and noisy latency measurement.
Why Single-Provider AI Inference Breaks at Scale
The GPU cloud market is still maturing. Unlike general-purpose compute — where AWS, GCP, and Azure have decades of reliability engineering — specialized GPU infrastructure experiences capacity constraints, regional outages, and pricing volatility that traditional workloads never see.
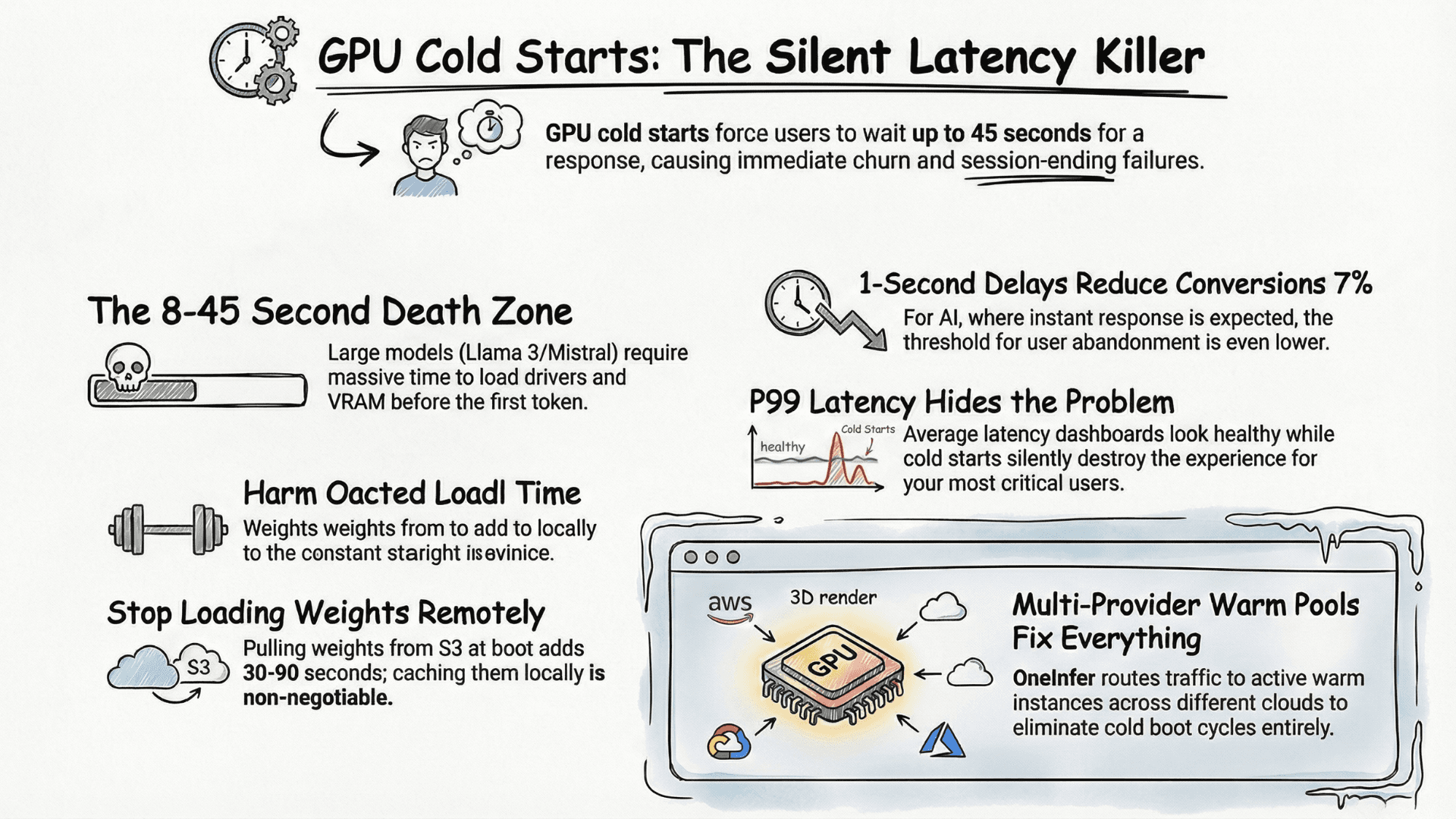
Lambda Labs, CoreWeave, Vast.ai — each is excellent for specific use cases and price points. None should be your only AI inference provider in production. When H100 spot capacity runs dry on one platform, your LLM serving pipeline needs somewhere to go immediately, automatically, and without your engineers waking up at 3AM.
This is why "best AI inference platform" rankings that only evaluate single-provider performance miss the most important production characteristic: what happens when that provider has a bad day?
The Four Core Routing Strategies
1. Cost-first routing
Route each request to the cheapest available GPU that meets your latency SLA. Ideal for async workloads — document processing, batch embeddings, offline fine-tuning — where 200ms of variance doesn't affect user experience. Across the top inference platforms in 2026, cost-per-token for equivalent hardware varies 30–60% by time of day and provider demand.
2. Latency-first routing
Route to the fastest warm instance regardless of cost. Essential for real-time chat, voice AI, or any user-facing low-latency LLM deployment where time-to-first-token is a product metric.
3. Model-aware routing
Llama 3 8B fits comfortably on an RTX 4090. Mixtral 8x7B needs an A100 80GB minimum. Routing should be model-aware so you're never paying H100 SXM rates for a workload that performs equally on an L40S at half the price.
4. Failover routing
When a provider returns an error, rate-limits your account, or has no available capacity, your router should automatically retry the next best provider — without the user seeing a failure or waiting through a timeout.
What Makes Multi-Provider Routing Hard in Practice
State synchronization across inference instances. If you're running multiple serving nodes, they all need to share provider health state. A provider failing for one node is almost certainly failing for all — but if each node maintains its own health state, you'll hammer a degraded provider with retries from every node before they independently agree it's down.
Token-level billing reconciliation. Different GPU cloud providers report token counts using different tokenizers, granularities, and definitions of "prompt" versus "completion" tokens. Cost-per-inference tracking breaks immediately if you assume uniformity.
Latency measurement noise. A static latency score per provider is nearly useless — you need a rolling exponential moving average updated on every request, not a number set at deploy time.
How OneInfer Handles This Natively
Rather than building this routing infrastructure yourself — which represents months of engineering time and ongoing maintenance — OneInfer's AI inference API abstracts all of this behind a single, OpenAI-compatible endpoint.
You make one API call. OneInfer's routing layer evaluates provider health, latency scores, model availability, and your configured cost/latency preference, then dispatches your request to the optimal GPU cloud in real time. If the selected provider fails mid-stream, automatic failover kicks in transparently before timeout.
Our unified observability dashboard gives you per-provider latency breakdowns, cost-per-request across every provider, and success rate trends — the data you need to make infrastructure decisions based on evidence, not instinct.
Research from Andreessen Horowitz's AI infrastructure team consistently shows multi-provider routing reduces average inference cost 30–50% versus single-provider, while simultaneously improving uptime.
A Practical Implementation Checklist
- 1Audit current provider usage by spend, P99 latency, and 30-day error rate per provider.
- 2Pick a routing strategy that matches workload type — cost-first for async, latency-first for real-time.
- 3Implement health checks before routing logic. Reliable signals are the foundation.
- 4Log every routing decision: provider selected, reason, actual latency, success/failure.
Multi-provider GPU routing is now table stakes for serious AI production. It's the difference between absorbing provider incidents invisibly and turning every GPU cloud hiccup into a user-facing outage. Start simple, measure everything, and automate the decisions your team is currently making manually.
To explore how OneInfer handles multi-provider routing out of the box, visit oneinfer.ai/products/model-apis or contact the team.
Run multimodal AI inference at production scale
OneInfer routes every request to the optimal GPU across multiple cloud providers in real time, with sub-500ms latency, AI-generated kernel optimization, and transparent pricing.
Frequently asked questions
+What is multi-provider GPU routing?
Multi-provider GPU routing dispatches each AI inference request to the optimal GPU cloud provider in real time based on price, latency, model availability, and provider health, rather than locking all traffic to a single provider.
+How much can multi-provider routing reduce inference costs?
Teams implementing multi-provider routing typically reduce average inference cost 30–50% versus single-provider setups while improving uptime, according to Andreessen Horowitz infrastructure research.
+What are the four core multi-provider routing strategies?
Cost-first routing for async workloads, latency-first routing for user-facing real-time features, model-aware routing that matches GPU tier to model size, and failover routing that automatically retries on the next provider when one fails.
+Is OneInfer's API OpenAI-compatible?
Yes. OneInfer's unified inference API is OpenAI-compatible, so existing OpenAI SDK code works against OneInfer with only an endpoint change, while routing across providers happens transparently behind that single API call.
+What's the hardest part of building multi-provider routing yourself?
State synchronization across nodes, token-level billing reconciliation across providers with different tokenizers, and noisy latency measurement that requires rolling exponential moving averages rather than static scores.