TL;DR
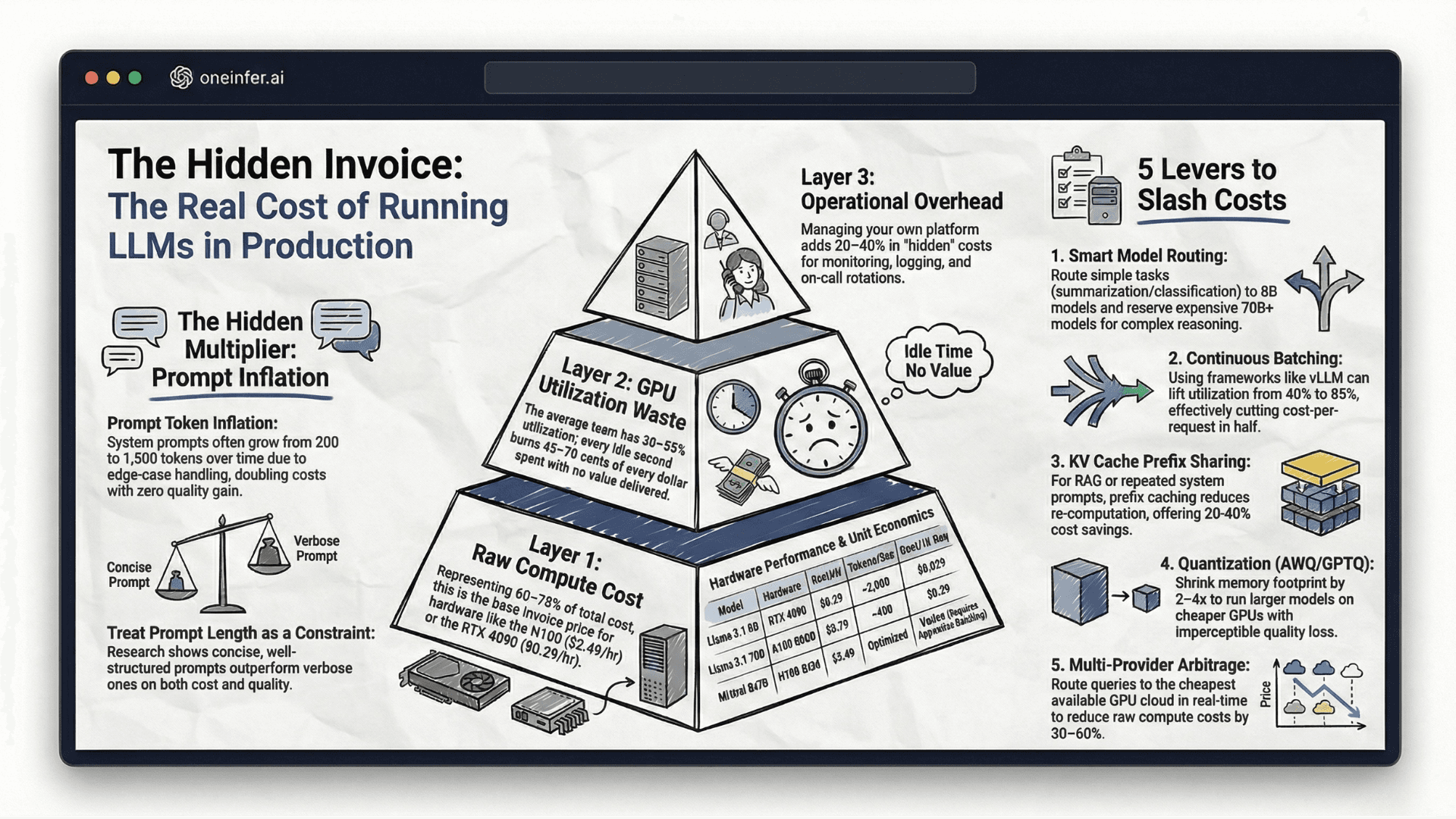
LLM inference cost has three layers: raw compute (60–75% of total), GPU utilization waste (typically 45–70 cents of every dollar wasted on idle GPU cycles), and operational overhead (20–40% added cost). On OneInfer, Llama 3.1 8B on RTX 4090 ($0.29/hr) costs ~$0.029 per 1,000 requests; Llama 3.1 70B on A100 80GB ($0.79/hr) costs ~$0.39 per 1,000 requests. The five highest-leverage cost reduction levers are model routing by complexity, continuous batching, KV cache prefix sharing, AWQ quantization, and multi-provider arbitrage.
The Three Cost Layers Nobody Fully Explains
When your GPU cloud bill arrives, the line item looks simple — dollars per GPU-hour. But your true cost-per-inference has three distinct layers hiding underneath that headline number.
Layer 1: Raw compute cost
This is the invoice line. On OneInfer: H100 SXM at $2.49/hr, A100 80GB at $0.79/hr, L40S at $0.59/hr, RTX 4090 at $0.29/hr. For most LLM workloads, raw compute represents 60–75% of total inference cost — but only when the other two layers are controlled.
Layer 2: GPU utilization waste
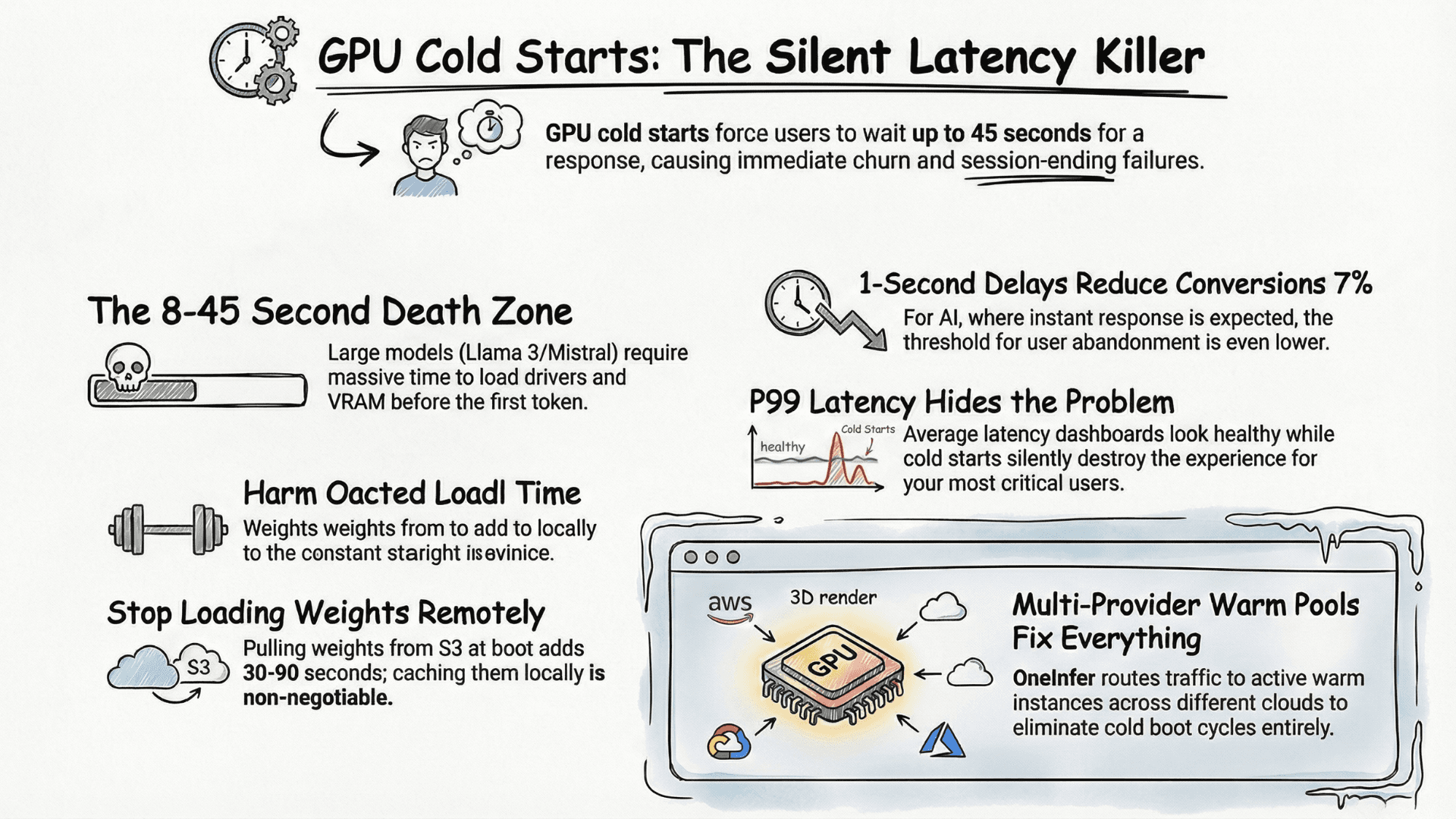
This is the cost almost nobody measures. If your GPU runs at 40% average utilization — typical without continuous batching — you're paying for 100% of the hardware and using 40%. Research from the MLSys community puts average GPU utilization across AI production teams at 30–55%. That means 45–70 cents of every dollar is wasted.
Layer 3: Operational overhead
Monitoring, logging, autoscaling engineering, incident response, on-call rotations — real cost that never appears on your GPU bill. For teams managing their own AI model deployment platform, operational overhead consistently adds 20–40% to true total cost.
Real Cost Estimates by Model and Hardware
Llama 3.1 8B on RTX 4090 ($0.29/hr): With continuous batching via vLLM, ~2,000 tokens/second. Assuming 500 input + 200 output tokens per request, ~10,000 requests per GPU-hour. $0.029 per 1,000 requests — extraordinarily cost-efficient for a production-grade open-source model.
Llama 3.1 70B on A100 80GB ($0.79/hr): Throughput drops to ~400 tokens/second. ~2,000 requests per GPU-hour. $0.39 per 1,000 requests. About 13x more expensive per request than 8B, for 2–3x quality improvement on complex reasoning.
Mixtral 8x7B (MoE) on H100 SXM ($2.49/hr): MoE loads all expert weights but activates only a subset per forward pass. With aggressive batching, effective cost approaches 70B dense — without it, you pay H100 prices for A100-level throughput.
The Hidden Multiplier: Prompt Token Inflation
One of the most consistently underestimated LLM cost drivers is prompt growth. A system prompt that starts at 200 tokens becomes 1,500 tokens six months later as edge cases, instructions, and tool definitions accumulate.
Token cost scales linearly with prompt length. If your average prompt doubles over a year, inference cost doubles with no corresponding output quality improvement. Anthropic's prompt engineering research consistently shows that concise, well-structured prompts outperform verbose ones on both quality and cost. Treat prompt length as a resource constraint.
The Five Cost Optimization Levers
1. Model routing by task complexity
Simple classification, short summarization, and basic Q&A don't require a 70B model. Route them to 8B and reserve expensive compute for complex tasks. OneInfer's Smart Aggregator handles this automatically.
2. Continuous batching
If you're not using vLLM or equivalent, you're leaving GPU utilization on the table. Continuous batching alone lifts utilization from 30–40% to 70–85% — roughly halving real cost-per-request.
3. KV cache prefix sharing
For RAG and shared-system-prompt apps, prefix caching eliminates re-computation. Free 20–40% cost reduction for many production deployments.
4. Quantization
AWQ INT4 cuts memory 2–4x, allowing larger models on smaller GPUs. Quality regression is imperceptible for most production tasks. AWQ Llama 3.1 8B fits on RTX 4090.
5. Multi-provider cost arbitrage
GPU pricing varies 30–60% across providers and time of day. Routing to the cheapest provider that meets your latency SLA — as OneInfer does automatically — reduces raw compute cost meaningfully.
What Sustainable AI Unit Economics Look Like
A financially healthy AI product models inference cost as a fixed percentage of revenue. For B2B SaaS that's typically 10–25%. For consumer products at scale, lower.
If inference cost is growing faster than revenue and you can't trace why, you likely have three concurrent problems: unoptimized batching, prompt inflation, and no multi-provider routing.
The teams who solve AI unit economics aren't using the cheapest hardware or smallest models. They're building intelligent AI infrastructure that matches compute to task complexity, eliminates waste at every layer, and gives them real-number visibility.
Start measuring your true cost-per-inference today. The number will surprise you. Once you can see it, the path to reducing it becomes concrete. Contact OneInfer to benchmark your stack.
Run multimodal AI inference at production scale
OneInfer routes every request to the optimal GPU across multiple cloud providers in real time, with sub-500ms latency, AI-generated kernel optimization, and transparent pricing.
Frequently asked questions
+How much does it cost to run Llama 3.1 8B in production?
Llama 3.1 8B on an RTX 4090 ($0.29/hr on OneInfer) with continuous batching runs roughly $0.029 per 1,000 requests at a 500-input / 200-output token profile.
+How much does Llama 3.1 70B cost per 1,000 requests?
On an A100 80GB at $0.79/hr with continuous batching, Llama 3.1 70B runs about $0.39 per 1,000 requests — roughly 13x the 8B cost for 2–3x quality on complex reasoning.
+What is the biggest hidden cost in running LLMs?
GPU utilization waste. Most teams run at 30–55% GPU utilization, meaning 45–70 cents of every dollar spent on compute is idle hardware. Continuous batching is the single highest-leverage fix.
+How does prompt length affect LLM inference cost?
Token cost scales linearly with prompt length. Prompts typically grow 3–7x over a year as features and edge cases accumulate, doubling or tripling inference cost with no quality improvement.
+What's a healthy ratio of AI inference cost to revenue?
For B2B SaaS, healthy AI unit economics keep inference cost at 10–25% of revenue. Consumer products at scale should aim lower.