TL;DR
Seven AI infrastructure mistakes that cost us months: (1) building custom infrastructure pre-PMF instead of using managed inference APIs; (2) no cost attribution by feature; (3) ignoring prompt token inflation; (4) single GPU provider; (5) underestimating self-hosting operational cost; (6) treating model updates as framework bumps; (7) delaying infrastructure vendor relationships. The playbook: managed serverless until traffic stabilizes, instrument everything from day one, multi-provider from week one.
Mistake 1: We Built Custom Infrastructure Before PMF
Six weeks architecting a Kubernetes-based multi-GPU orchestration system before a single paying customer. When we launched, real usage looked nothing like what we'd designed for — we'd over-built for batch and under-built for the interactive low-latency use case our users actually cared about.
Right approach pre-PMF: managed AI inference APIs.Together AI, Replicate, or OneInfer's serverless tier give you production-grade inference with zero infrastructure overhead. Pay the higher per-token cost — it's worth it to learn what users actually need.
Mistake 2: We Didn't Attribute Inference Costs to Features
GPU bill arrived. High. We had no idea which features were responsible.
When you can't attribute AI inference cost to specific features or user segments, you cannot make rational optimization, deprecation, or pricing decisions. Tag every inference call with feature name, user tier, and request type from day one. Helicone is a lightweight observability proxy that adds cost attribution to any OpenAI-compatible API call.
Mistake 3: We Assumed Our Prompt Would Stay the Same Size
Launched with a 400-token system prompt. Eight months later: 2,800 tokens. Every edge case, capability, instruction layered in.
By month eight, inference cost per request had grown 600% — not from compute-intensive features but from prompt ballooning across feature branches. We were shipping "nearly free" features without separately tracking prompt vs completion token costs.
Establish an internal prompt token budget. Treat growth as a deliberate, costed decision.
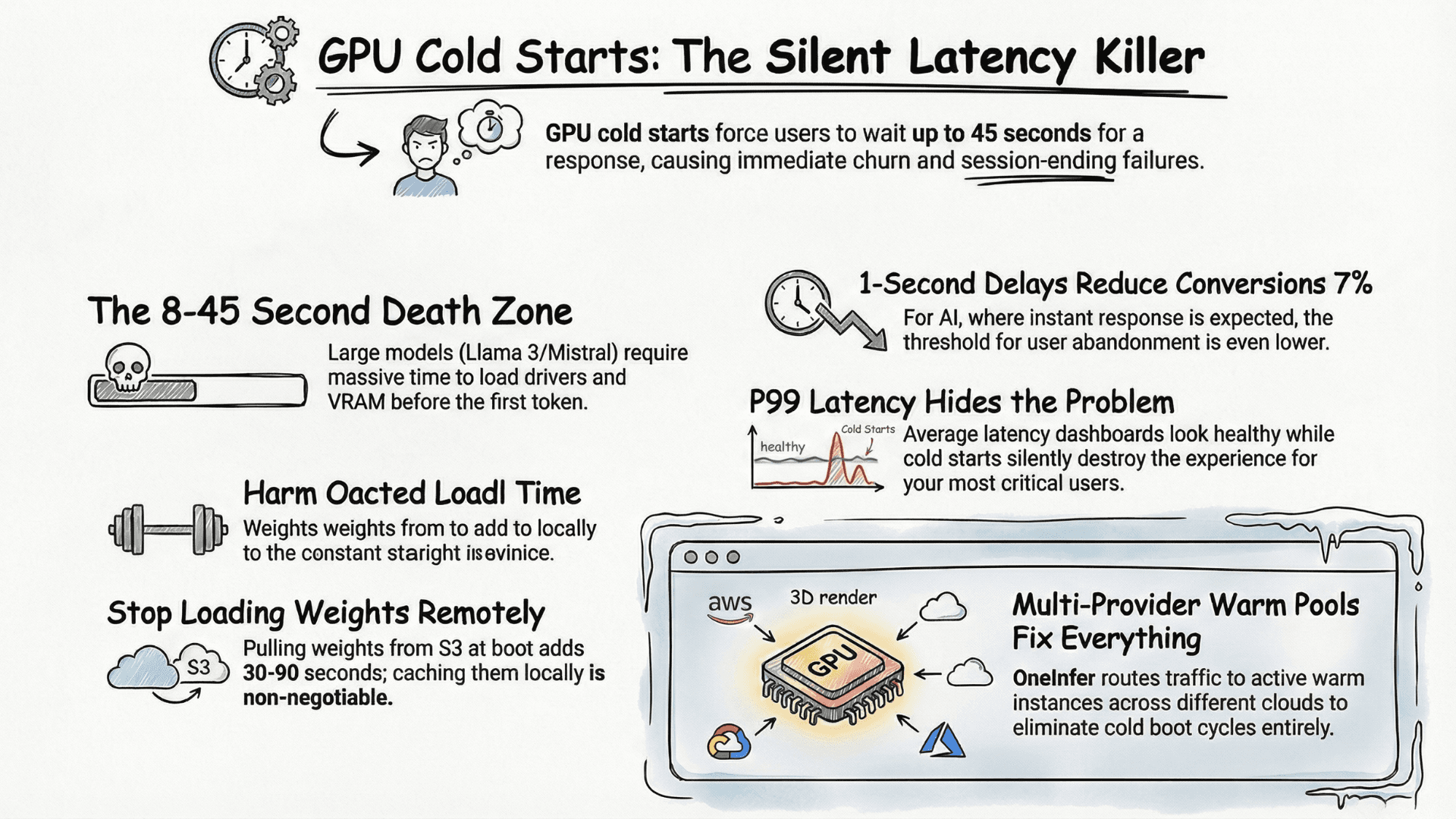
Mistake 4: We Used One GPU Provider for Everything
Three months in, our provider had a 4-hour outage during our highest-traffic Saturday afternoon. More insidiously, without a second provider as a baseline, we had no way to detect subtle performance degradation — measuring against our own historical numbers, which were also from a degraded state.
We rebuilt around OneInfer's multi-provider routing after that outage. Six months later than it should have been. For any startup evaluating top inference platforms in 2026, multi-provider support should be a first-order selection criterion.
Mistake 5: We Underestimated the Operational Cost of Self-Hosting
Open-source models are free to download. Not free to run. We spent ~30% of backend engineering capacity on model infrastructure — vLLM updates, GPU memory fragmentation, batching configs, CUDA version conflicts.
Financial break-even between self-hosting and managed: typically $10K–$30K/month inference spend. Below that threshold, engineering overhead exceeds the savings. Andreessen Horowitz's AI cost analysis covers this depth.
Mistake 6: We Didn't Plan for Model Updates as a Process
Major model release. We assumed a day. Took three weeks. Validating new model on use cases, A/B-testing quality, coordinating cutover, maintaining rollback. We now treat model updates as formal deployments with two-week minimum runway and shadow-mode validation.
Mistake 7: We Delayed Talking to Our Infrastructure Vendors
Treated GPU provider as a pure commodity vendor — signed up online, never spoke to anyone. Capacity crisis: no relationship, no escalation, no visibility. The AI infrastructure space is small and relationship-driven. Engaging early — before crisis — delivers disproportionate value.
What We'd Do Differently Starting Today
- 1Use managed serverless LLM inference until consistent traffic patterns emerge
- 2Instrument costs at the feature level from day one
- 3Keep prompt size on an explicit budget
- 4Use multi-provider GPU infrastructure from week one
- 5Treat model updates as versioned deployments
- 6Talk to infrastructure vendors early
None were sophisticated mistakes. All were predictable in retrospect — which is exactly why writing them down matters. Visit oneinfer.ai or contact the team.
Run multimodal AI inference at production scale
OneInfer routes every request to the optimal GPU across multiple cloud providers in real time, with sub-500ms latency, AI-generated kernel optimization, and transparent pricing.
Frequently asked questions
+When should an AI startup build its own inference infrastructure?
Build your own when you have consistent traffic patterns, clear model requirements, and the engineering capacity to maintain it. Below roughly $10–30K/month inference spend, managed APIs are typically cheaper than self-hosting once you account for engineering time.
+What's the biggest AI infrastructure mistake startups make?
Building custom infrastructure before product-market fit. Pre-PMF, traffic patterns are unknown — over-engineering for guesses produces infrastructure that doesn't match real workloads. Use managed inference APIs until usage stabilizes.
+How fast does prompt size grow in production?
Typical production prompts grow 3–7x over 12 months as edge cases, instructions, and tool definitions accumulate. Treat prompt token growth as a budgeted decision, not a free variable.
+Should I use multiple GPU providers from launch?
Yes. Multi-provider GPU infrastructure is both a reliability hedge and a competitive intelligence tool — it gives you a comparison baseline that makes provider degradation detectable before it surfaces as user-facing incidents.
+How long do AI model updates actually take in production?
Plan two weeks minimum for major model updates. You need to validate the model on your use cases, run A/B tests for quality, coordinate cutover across GPU nodes, and maintain rollback capability through the entire process.