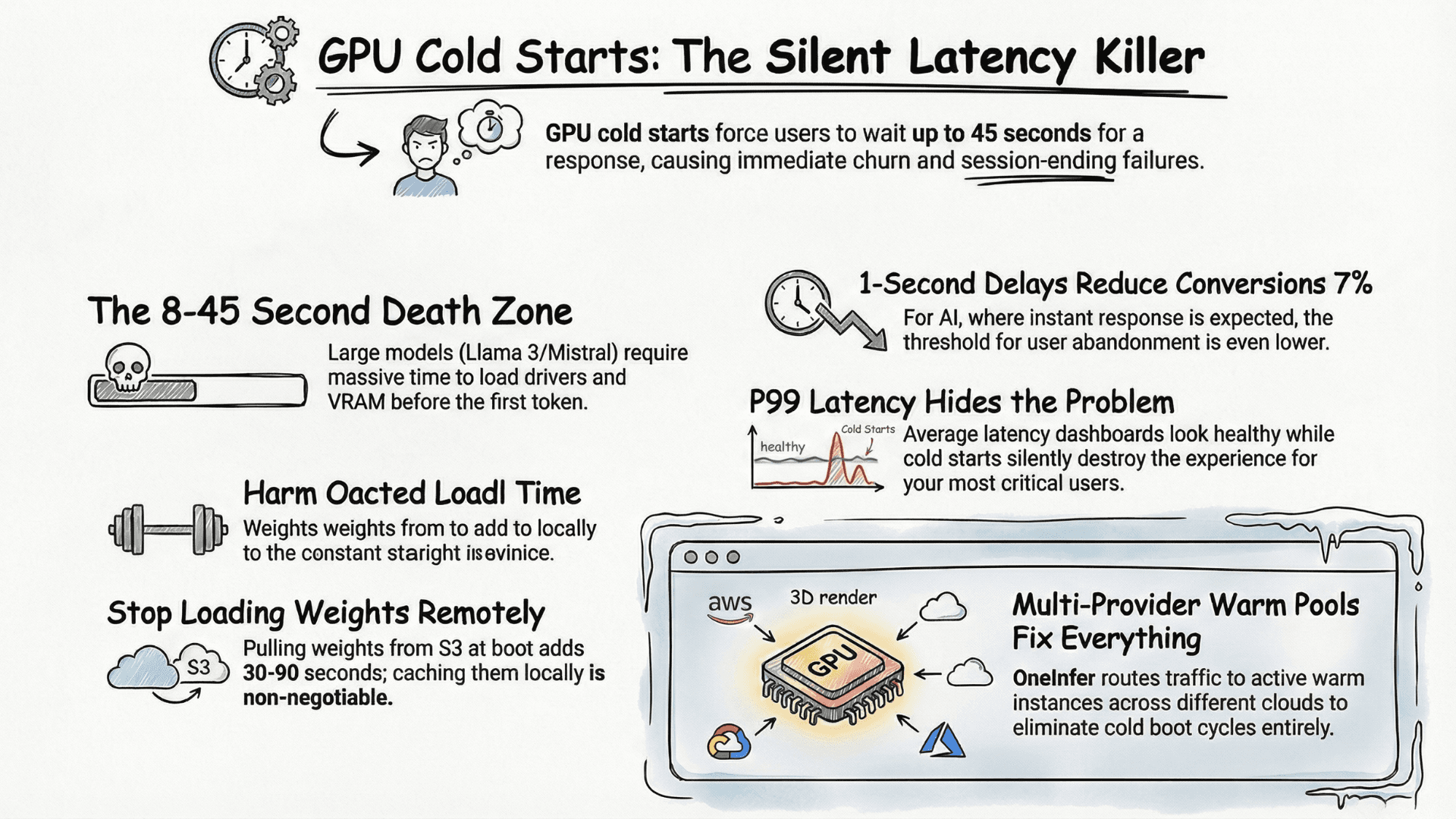
TL;DR
Four interventions reduced our GPU bill 60% while serving 3x volume: (1) model routing by task complexity using a lightweight BERT classifier shifted 62% of traffic from 70B to 8B for −35% total cost; (2) vLLM continuous batching tuning lifted utilization from 38% to 71% for −46% cost-per-request; (3) OneInfer multi-provider arbitrage saved an additional 28% raw GPU cost; (4) AWQ INT4 quantization for internal workloads cut GPU count 40%.
Where We Started: High Spend, Zero Visibility
Single GPU provider, on-demand A100 80GB instances, standard vLLM setup. No autoscaling. No batching optimization. No cost attribution by model or endpoint. The bill was high and growing — but more critically, it was completely opaque.
The first intervention was instrumentation. Every inference request got tagged with model ID, endpoint name, prompt token count, completion token count, GPU node ID, and latency. We streamed this into ClickHouse and built a Grafana dashboard within 24 hours.
What we found: 70% of inference volume was routed to our 70B model for tasks an 8B model handles with comparable quality. We were paying top-tier AI inference cost for commodity-quality work.
Intervention 1: Model Routing by Task Complexity (-35%)
We built a lightweight complexity classifier — small BERT-based model on CPU — that scores each incoming request before routing. Short questions, simple classification, basic summarization → Llama 3.1 8B on RTX 4090. Complex reasoning, long-form generation → 70B on A100.
The classifier adds 5–8ms per request, imperceptible. 62% of traffic shifted from 70B to 8B. Cost-per-request for that traffic dropped 13x. Approximately 35% off total GPU spend. Largest single intervention.
Intervention 2: Continuous Batching Tuning (-46% Cost-Per-Request)
Default vLLM. GPU utilization averaging 38%. Paying for 100%, using 38%.
Tuning changes:
- 1
--max-num-batched-tokens: 8,192 → 32,768 - 2
--max-num-seqs: → 256 - 3prefix caching enabled
After: utilization 38% → 71%. Same hardware, same cost, nearly double effective throughput. Cost-per-request dropped 46% on existing traffic.
Intervention 3: Multi-Provider Arbitrage via OneInfer (-28% Raw GPU Cost)
After model and batching optimization, we turned to GPU procurement.
Integrated OneInfer's Smart Aggregator. The routing engine compares real-time pricing and availability across providers and routes each request to the cheapest GPU meeting our latency threshold (800ms TTFT ceiling).
Off-peak: traffic routes to lower-cost providers. Peak: routes to premium capacity automatically. Over 30 days, effective cost-per-token dropped an additional 28%. Transparent pricing also eliminated the billing surprises we'd come to expect.
Intervention 4: Quantization for Non-Critical Workloads (-40% GPU Count Internal)
For internal tooling — developer productivity features, internal search, content drafting — we moved from FP16 to AWQ INT4. Halved VRAM footprint, twice as many model instances per GPU node.
Quality tradeoff for internal: imperceptible. For customer-facing where output quality is differentiation: kept FP16. GPU count for internal tier dropped 40%.
The Full Accounting
- 1Model routing: −35% total inference cost
- 2Batching optimization: −46% cost-per-request on existing traffic
- 3Multi-provider routing via OneInfer: −28% raw GPU cost
- 4Quantization for internal: −40% internal tier GPU count
Net result: 60%+ reduction in total GPU spend while serving 3x volume.
Reducing LLM inference cost is layered. No single intervention closes the gap. Optimize simultaneously at model selection, serving config, hardware procurement, and efficiency layers. Start with instrumentation — you cannot optimize what you cannot see.
To explore how OneInfer handles procurement and routing, visit oneinfer.ai or talk to the team.
Run multimodal AI inference at production scale
OneInfer routes every request to the optimal GPU across multiple cloud providers in real time, with sub-500ms latency, AI-generated kernel optimization, and transparent pricing.
Frequently asked questions
+How can I reduce my GPU inference cost by 60%?
Combine four interventions: model routing by task complexity (−35%), vLLM continuous batching tuning (−46% cost-per-request), multi-provider GPU arbitrage (−28% raw cost), and AWQ INT4 quantization on non-critical workloads (−40% GPU count for internal tier).
+What is the single highest-impact GPU cost optimization?
Model routing by task complexity. Most teams route 60–70% of traffic to oversized models. Routing simple tasks to 8B models instead of 70B cuts cost-per-request 13x for that traffic — typically 30–40% off total GPU spend.
+How do I tune vLLM for better GPU utilization?
Set --max-num-batched-tokens to 16,384–32,768 for throughput, --max-num-seqs to 256+ for concurrency, and always enable --enable-prefix-caching for RAG. These changes typically lift GPU utilization from 30–40% to 65–80%.
+How does OneInfer's multi-provider arbitrage save 28%?
OneInfer's Smart Aggregator continuously evaluates real-time pricing and availability across multiple GPU clouds and routes each request to the cheapest provider that meets your configured latency SLA — capturing 30–60% spot price variation across providers automatically.
+Should I use AWQ INT4 quantization for production?
Use AWQ INT4 for internal tooling and non-customer-facing workloads where it cuts memory 2–4x with imperceptible quality regression. For customer-facing features where output quality is direct differentiation, keep FP16.