TL;DR
Seven hidden AI infrastructure costs blindside scaling teams: idle GPU billing on instances left running between jobs, cross-region data transfer fees on every inference call, oversized models multiplying every other cost 13x, unplanned retraining cycles, inefficient request handling without batching, integration maintenance overhead, and traffic spikes without budget guardrails. The cost-control checklist: monitor utilization, right-size models, co-locate endpoints, automate retraining, enable batching, consolidate integrations, alert at 50%/75% budget.
Why Hidden Costs Dominate AI Infrastructure Spend
The AI cost conversation is almost entirely focused on model access — API pricing per token, training compute, fine-tuning. But the majority of total AI operational spend comes from infrastructure costs that teams consistently fail to model: storage, data movement, idle compute, operational overhead, and the compounding cost of inefficiency at scale.
According to Andreessen Horowitz's AI infrastructure research, the model is frequently the cheapest part. What surrounds it — serving, monitoring, scaling, data movement — is where budgets break. Teams evaluating only model pricing are optimizing 20% of cost structure and ignoring 80%.
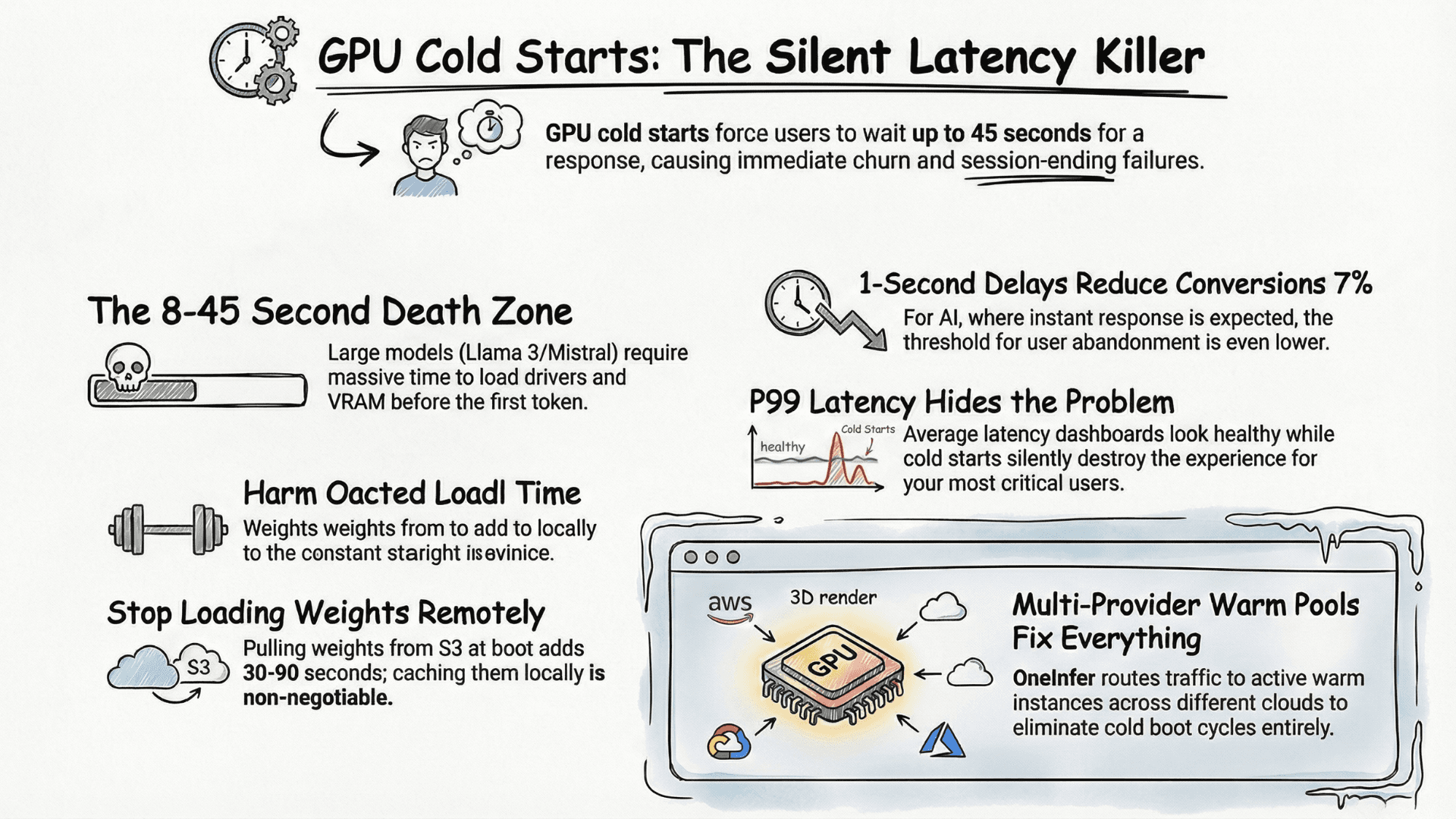
Surprise 1: GPU Instances Bill When You're Not Using Them
The most common and avoidable surprise. An idle H100 at $2.49/hr costs over $1,800/month doing nothing. Automate GPU lifecycle: shut down when utilization drops below threshold, scale up proactively before traffic returns.
OneInfer's dedicated endpoint model replaces unpredictable usage-based GPU billing with infrastructure that scales intelligently.
Surprise 2: Data Transfer Fees Compound Silently
Every byte moved between cloud regions has a cost. At small scale, invisible. At production AI scale — with large prompt contexts, embedding payloads, multi-modal inputs across AZs — egress can outpace compute.
Inference endpoints in US-East with data pipeline in EU-West pays egress on every single call. Keep endpoints geographically co-located with primary data sources. OneInfer's regionalized API minimizes cross-region movement.
Surprise 3: Model Size Is a Multiplier on Every Other Cost
Larger models don't just consume more memory. They require premium hardware, longer per-request runtime, larger KV caches, and more aggressive autoscaling margins. Every inefficiency in your serving stack is multiplied by model size.
Teams deploying 70B for 8B-quality tasks pay 13x more per request — not 8x. Benchmark smaller, quantized, or distilled variants before committing.
Surprise 4: Retraining Costs Are Not One-Time
Model drift is inevitable. As production data distribution shifts, quality degrades. Each unplanned retraining cycle consumes GPU-hours, engineering attention, and pipeline capacity. Automate retraining pipelines and schedule compute-intensive jobs during off-peak GPU pricing windows. Weights & Biases provides experiment tracking; OneInfer handles seamless model updates.
Surprise 5: Inefficient Request Handling at Scale
Serving each request in isolation — no batching, no KV cache reuse, no prefix sharing — pays full compute cost for work efficient systems handle at a fraction. Continuous batching alone improves utilization 30–40% → 70–85%, cutting cost-per-request roughly in half.
vLLM's continuous batching is the production standard. Any top 10 model deployment platform should have it default-on.
Surprise 6: Integration Overhead Has a Salary Cost
The most quietly damaging cost is engineering time on fragile integration layers. Custom monitoring pipelines, provider-specific adapters, manual failover scripts, homegrown batching logic — all require maintenance.
OneInfer's unified inference API provides a single endpoint that routes across providers, handles failover, and surfaces observability — replacing the custom integration layer that consumes weeks to build and months to maintain.
Surprise 7: Traffic Spikes Without Spend Guardrails
A successful launch, viral moment, or enterprise onboarding can double or triple workload in hours. Without autoscaling guardrails and budget thresholds, the spike lands on your monthly bill before finance is aware.
Implement budget alerts at 50%, 75%, 90% — not 100%, by which point damage is done. OneInfer's platform embeds cost guardrails as a first-class feature.
The Cost-Control Checklist
- 1Monitor GPU utilization; alert below 40% — idle GPU is money burning.
- 2Right-size models by benchmarking smaller variants on production tasks.
- 3Keep inference endpoints geographically co-located with data sources.
- 4Automate retraining pipelines.
- 5Enable continuous batching and prefix caching before scaling.
- 6Consolidate integration layer to one API abstraction.
- 7Set budget alerts at 50% and 75%.
Visit oneinfer.ai or contact the team.
Run multimodal AI inference at production scale
OneInfer routes every request to the optimal GPU across multiple cloud providers in real time, with sub-500ms latency, AI-generated kernel optimization, and transparent pricing.
Frequently asked questions
+What are the biggest hidden AI inference costs?
Idle GPU billing, cross-region data transfer fees, oversized model multipliers, unplanned retraining cycles, inefficient request handling without batching, integration maintenance overhead, and unmanaged traffic spikes. Together these typically dwarf raw model API pricing.
+How much does an idle H100 GPU cost per month?
An H100 at $2.49/hour costs over $1,800/month if left running idle 24/7. Automated lifecycle management that scales to zero between traffic windows is non-negotiable for cost control.
+How do I prevent data transfer fees on AI inference?
Keep inference endpoints geographically co-located with their primary data sources. Cross-region egress fees compound rapidly at production AI scale and can exceed raw compute cost for global deployments.
+At what cost should I set AI budget alerts?
Set alerts at 50%, 75%, and 90% of monthly GPU budget. Setting alerts at 100% means damage is already done — earlier thresholds give engineering time to investigate before billing close.
+How does continuous batching reduce AI inference cost?
Continuous batching processes requests as they arrive rather than waiting for static batches, lifting GPU utilization from typical 30–40% to 70–85% — cutting real cost-per-request roughly in half with no hardware or model changes.