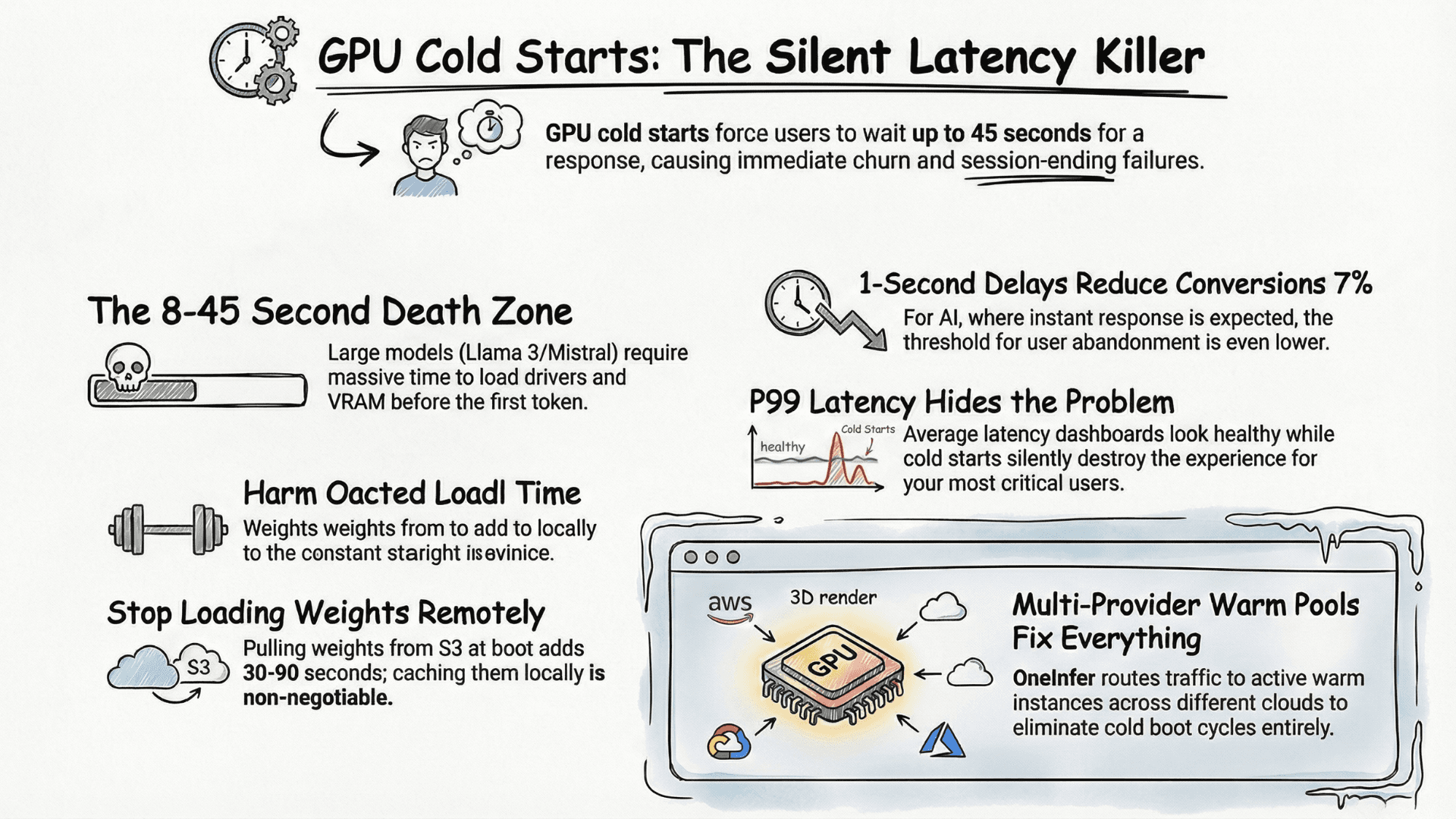
TL;DR
Sub-millisecond AI inference requires disciplined engineering across five layers: (1) hardware foundation — H100 SXM or A100 80GB with model fitting fully in VRAM; (2) FP16/AWQ model optimization with operator fusion and TensorRT-LLM compilation; (3) multi-layer caching — exact-match Redis, semantic similarity, and KV cache prefix sharing yielding 60–80% hit rates; (4) Triton/TensorRT-LLM with continuous batching; (5) production observability with TTFT, inter-token, and P99 metrics tracked separately.
Why Sub-Millisecond Is the Right Target
Many teams accept 50–100ms latency as "good enough" and stop optimizing. Strategic mistake.
First, user tolerance is declining. The top inference platform competitors deploy today sets the floor users expect tomorrow. Second, lower per-request latency directly increases requests served per GPU-hour — sub-millisecond is simultaneously a performance improvement and a cost reduction.
Google's research on speed demonstrates 100ms improvements correlate with measurable engagement gains across categories.
Layer 1: Build the Right Hardware Foundation
NVIDIA H100 SXM with 80GB HBM3 and NVLink is current top-tier for latency-critical inference. A100 80GB remains excellent for most workloads at significantly lower cost — contact OneInfer to discuss the best price/performance tier for your workload.
Critically, your entire model must fit in GPU VRAM. The moment inference spills to system RAM or NVMe, your latency floor jumps by orders of magnitude — no software optimization recovers from that.
For distributed inference, NVLink delivers 900GB/s inter-GPU bandwidth. InfiniBand or RoCE at 100Gbps+ is the equivalent at cluster level.
Layer 2: Optimize Your Model for Inference Speed
The model you train and the model you serve can be different artifacts. Training optimizes accuracy. Serving optimizes speed, memory, and cost.
FP16 from FP32 halves memory and roughly doubles throughput with negligible quality loss for most production tasks. Default serving format.
Operator fusion merges sequences into single kernel passes, eliminating memory roundtrips. FlashAttention is the canonical example.
AWQ INT4 cuts memory 4x with minimal regression. NVIDIA TensorRT-LLM automates many optimizations for NVIDIA hardware.
Layer 3: Build a Multi-Layer Caching Architecture
Significant percentages of inference requests are computationally redundant. The same or semantically equivalent queries asked repeatedly. A multi-layer cache eliminates redundant computation.
Layer 1: Exact-match caching via Redis. Identical inputs return cached outputs at submicrosecond latency.
Layer 2: Semantic similarity caching via vector DB. "What's your refund policy" and "how do I return a product" return the same cached response after a fast nearest-neighbor lookup.
Layer 3: KV cache prefix sharing. Eliminates recomputation of shared prompt prefixes — 20–40% throughput improvement free for RAG.
Combined: 60–80% cache hit rates on production traffic, serving the majority of requests at microsecond latency.
Layer 4: Configure Your Serving Framework for Maximum Throughput
NVIDIA Triton Inference Server + TensorRT-LLM is the production standard for latency-critical inference on NVIDIA hardware. Triton handles request batching, model management, concurrent execution. TensorRT-LLM handles model compilation to GPU-specific instruction sets.
Continuous batching — processing requests as they arrive rather than waiting for a static batch — is the most impactful serving change for LLM workloads. Eliminates batch wait time tax while maintaining high utilization.
Smart batching dynamically adjusts batch size based on queue depth and SLA — larger batches when budget is wide, smaller when low latency is priority.
Layer 5: Deploy with Production-Grade Observability
Sub-millisecond targets require continuous measurement. Latency drifts due to model updates, traffic changes, hardware degradation, batching config drift.
Metrics that matter: TTFT, inter-token latency, P99 end-to-end — tracked separately, never averaged. P50 can look excellent while P99 is catastrophic for a subset.
Prometheus with Grafana provides infrastructure. Arize AI provides AI-specific production ML monitoring. OneInfer's unified observability surfaces per-provider latency, token speed, and queue depth in one view.
The Sub-Millisecond Implementation Sequence
- 1Establish current baseline with realistic traffic — P50, P95, P99.
- 2Apply FP16 first. Zero-risk for most workloads, largest single improvement.
- 3Implement continuous batching. Measure throughput improvement.
- 4Layer in caching — exact-match first, then semantic.
- 5Compile with TensorRT-LLM if on NVIDIA. Measure additional gains.
The teams achieving consistent sub-millisecond latency aren't the ones with the most sophisticated infrastructure — they're the ones with the most disciplined measurement practices. Explore OneInfer's platform or talk to the team.
Run multimodal AI inference at production scale
OneInfer routes every request to the optimal GPU across multiple cloud providers in real time, with sub-500ms latency, AI-generated kernel optimization, and transparent pricing.
Frequently asked questions
+Can AI inference really run in sub-millisecond latency?
Yes — for cached or semantically-cached requests at the application edge, sub-millisecond is achievable. For full LLM inference, sub-millisecond requires aggressive optimization across hardware, model precision, caching, and serving framework configuration.
+What is the best GPU for sub-millisecond inference?
NVIDIA H100 SXM with 80GB HBM3 is current top-tier. A100 80GB is excellent for most production workloads at significantly lower cost. Critical requirement: the entire model must fit in GPU VRAM.
+How does multi-layer caching reduce AI inference latency?
Three layers — exact-match Redis caching, semantic similarity vector lookup, and KV cache prefix sharing — collectively achieve 60–80% cache hit rates on production traffic, serving the majority of requests at microsecond latency rather than millisecond inference time.
+What metrics matter for sub-millisecond inference monitoring?
Track TTFT (time-to-first-token), inter-token latency, and P99 end-to-end generation time separately. Never average them. P50 can look excellent while P99 is catastrophically slow for a subset of users.
+Should I use FP16 or FP32 for production inference?
FP16 should be the default. Halves memory footprint and roughly doubles throughput with negligible quality regression for virtually all production text generation, classification, and summarization tasks.