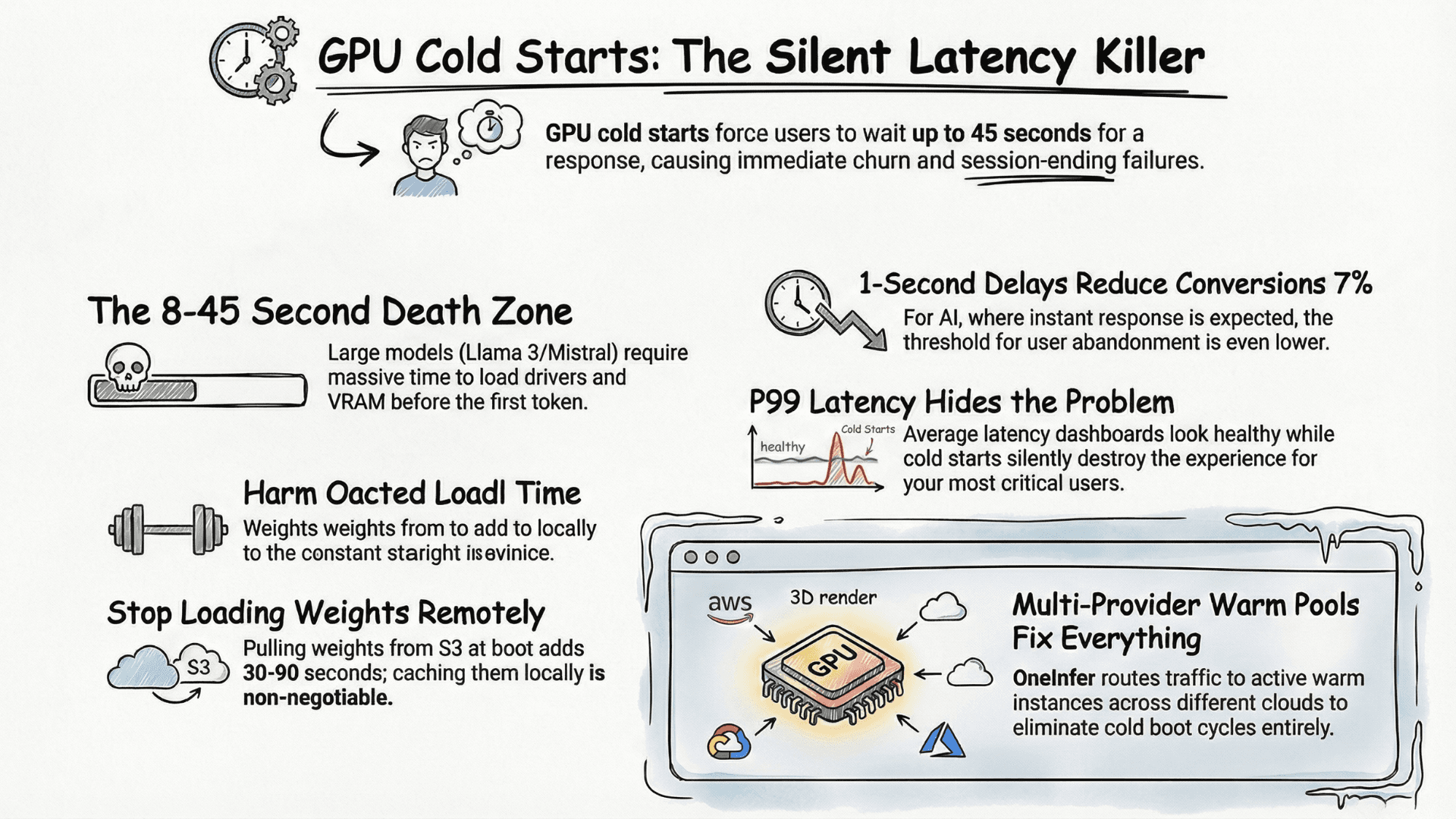
You found the model. It is on Hugging Face. The benchmark numbers look right, the license is clean, and the architecture fits what you are building. You copy the model ID, open your terminal, and start piecing together the setup.
Then the questions start. Do you have enough VRAM? Is Ollama installed? Does this model architecture work with llama.cpp? How much memory does KV cache consume on top of the weights? You can estimate, read the model card, guess, and then spend hours debugging a deployment that fails because one number was off.
OneInfer Edge, part of the oneinfer.ai AI inference control plane, removes those questions before you run a single command.
The Problem With Self-Hosting Hugging Face Models Today
Deploying an open-source model locally is not one decision. It is four decisions stacked on top of each other.
Which serving library works with this model architecture? Do you have it installed? Does your hardware actually have enough memory, accounting for weights, KV cache, and the serving library's own overhead? Is all of this going to work together on your specific machine?
Most tools answer none of these questions. They give you a deployment command and let you find out at runtime. OneInfer Edge answers all four before you click deploy.
How the Self-Hosting Flow Works in OneInfer Edge
Open the Self Hosting section under Model Hosting. On the left, you get a deployment panel with Hugging Face and OneInfer Catalog options. Paste any Hugging Face model ID (owner/model) or a full Hugging Face URL into the Model field, or browse validated models from the catalog.
On the right, your Local Hardware panel is already populated. OneInfer Edge scans the machine when the app opens and shows the hostname, OS version, architecture, CPU, vCPU count, physical cores, RAM, GPU count, VRAM, utilization, and driver version where available.
Key Insight
For Apple Silicon machines, OneInfer Edge reads the unified memory pool directly. For NVIDIA systems, it reads discrete VRAM, utilization percentage, and CUDA driver version. For AMD systems, it reads ROCm-reported memory.
Inference Readiness: What Gets Checked
Once you enter a model, OneInfer Edge performs an Inference Readiness check. It cross-references the model architecture and format, the serving libraries available on your machine, and your specific hardware. The result is a per-library verdict that is specific to this model on this system.
Example serving library verdicts
Ollama and llama.cpp are marked installed for GGUF models on compatible Apple Silicon setups. SGLang and TensorRT-LLM are unsupported on non-NVIDIA hardware because they require CUDA or NVIDIA-specific runtimes. PyTorch is unsupported for raw GGUF because PyTorch cannot load GGUF files directly.
Unsupported does not always mean missing. Sometimes it means the hardware or model format cannot work with that runtime. OneInfer Edge makes that distinction before you waste time installing libraries that cannot succeed.
The VRAM Breakdown, Computed Against Your Hardware
The File Summary is not a generic estimate. It is computed against your detected machine and selected serving library. For Qwen2.5-0.5B-Instruct-GGUF on a 12 GB Apple unified-memory machine with Ollama, the total estimate is 4.18 GB: 1.18 GB model weights, 1.00 GB KV cache estimate, and 2.00 GB serving library overhead.
Key Insight
Hardware Ready: The Go / No-Go Signal
After the readiness check resolves, OneInfer Edge gives you a clear verdict. For an Apple M5 MacBook Pro with 12 GB unified memory running Qwen2.5-0.5B-Instruct-GGUF through Ollama, the verdict is Hardware Ready.
The confirmation explains that the system supports the model with model weights, KV cache, and serving library overhead. The memory bar shows current utilization so you can see exactly how much headroom remains for other processes.
Key Insight
One-Click Deploy and Local Endpoint Registration
Once hardware is confirmed ready, deploy. OneInfer Edge launches the model through the selected serving library and registers the local deployment as a live inference endpoint within the oneinfer.ai inference control plane.
A local endpoint such as http://127.0.0.1:11434/v1 is now registered with OneInfer. You can copy the URL for direct use in any OpenAI-compatible application, use it in a route, or delete it to deregister the deployment and stop the local server.
Use in route adds the local deployment as a routing candidate in OneInfer's intelligent inference routing layer, so traffic can flow to your local machine or fail over to OneInfer's cloud model APIs when local capacity is exceeded.
Complete Deployment Flow: Zero to Running Model
- 1Open Self Hosting in OneInfer Edge. Your local hardware profile is populated automatically.
- 2Enter your Hugging Face model ID or URL, or choose a curated model from the OneInfer Catalog.
- 3Review Inference Readiness to see which serving libraries are installed and compatible.
- 4Confirm Hardware Ready status and the full VRAM estimate: weights plus KV cache plus serving library overhead.
- 5Deploy and register the local OpenAI-compatible endpoint for direct use or hybrid routing.
The Open-Source Self-Hosting Philosophy
OneInfer Edge is built on the belief that self-hosting should be a genuine alternative to managed cloud inference, not a punishment for developers who do not want to pay per token.
When you run models locally through OneInfer Edge, your model weights stay on your hardware. Your prompts never leave your machine. Your inference cost is your electricity bill and hardware amortization, not a per-token bill that scales with every request.
For teams that need both local and cloud, the registered local endpoint integrates with OneInfer's intelligent routing layer. You can run a model locally through OneInfer Edge and route overflow traffic to the OneInfer cloud model APIs without changing your application's API calls.
Key Insight
Frequently Asked Questions
+How does OneInfer Edge check if my hardware can run a Hugging Face model?
OneInfer Edge scans your local machine at launch, detecting GPU model, VRAM or unified memory, OS, architecture, CPU, and RAM. When you select a model, it computes model weights, KV cache, and serving library overhead, then compares that requirement against available accelerator memory.
+Which serving libraries does OneInfer Edge support?
OneInfer Edge detects and evaluates Ollama, llama.cpp, SGLang, TensorRT-LLM, and PyTorch. For each model and hardware combination, it shows which libraries are installed and compatible with your setup.
+Why is TensorRT-LLM shown as unsupported on my Mac?
TensorRT-LLM is an NVIDIA-only runtime that requires CUDA and an NVIDIA GPU. On Apple Silicon machines and systems without NVIDIA hardware, OneInfer Edge correctly marks it as unsupported.
+Why is PyTorch unsupported for GGUF models?
Raw PyTorch cannot load GGUF quantized model files directly. GGUF is designed for runtimes like Ollama and llama.cpp, so OneInfer Edge marks PyTorch as unsupported for GGUF models because of format incompatibility.
+Does OneInfer Edge work with Apple Silicon Macs?
Yes. OneInfer Edge detects Apple Silicon chips and unified memory capacity, recommends compatible serving libraries such as Ollama and llama.cpp, and calculates memory requirements against unified memory rather than discrete VRAM.
+Can I use the local endpoint with other AI coding tools?
Yes. OneInfer Edge registers local deployments as OpenAI-compatible endpoints such as http://127.0.0.1:11434/v1. Any tool that accepts a custom base URL can use the deployment.
+What is the VRAM requirement to run Qwen2.5-0.5B-Instruct-GGUF locally?
Running Qwen2.5-0.5B-Instruct-GGUF through Ollama requires approximately 4.18 GB of accelerator memory: 1.18 GB for model weights, 1.00 GB estimated for KV cache, and 2.00 GB for serving library overhead.
+What is OneInfer Edge?
OneInfer Edge is a local AI inference control plane by oneinfer.ai. It scans hardware, checks serving library compatibility, computes VRAM requirements, deploys Hugging Face models locally, and registers local endpoints for hybrid routing.
Deploy your first Hugging Face model locally in under five minutes
OneInfer Edge scans your hardware, checks your serving libraries, and gives you a Hardware Ready verdict before you run a single command. No guessing. No failed deployments.